☁️ Agnostic – On gremlins and graphs
Cloud agnostic series
- Depending on a colour
- Depending on a colour Pt. 2 - Needs, Possibilities and Limitations
- Cloud Agnostic - introducing the AheadDockerized .NET Solution
- ☁️ Agnostic - Storing & serving files
- ☁️ Agnostic - Messaging between servers with RabbitMQ (Queueing)
- ☁️ Agnostic – Messaging between servers with RabbitMQ (Publish/Subscribe)
- ☁️ Agnostic – Intermezzo: Insightful spans with OpenTelemetry
- ☁️ Agnostic – On gremlins and graphs
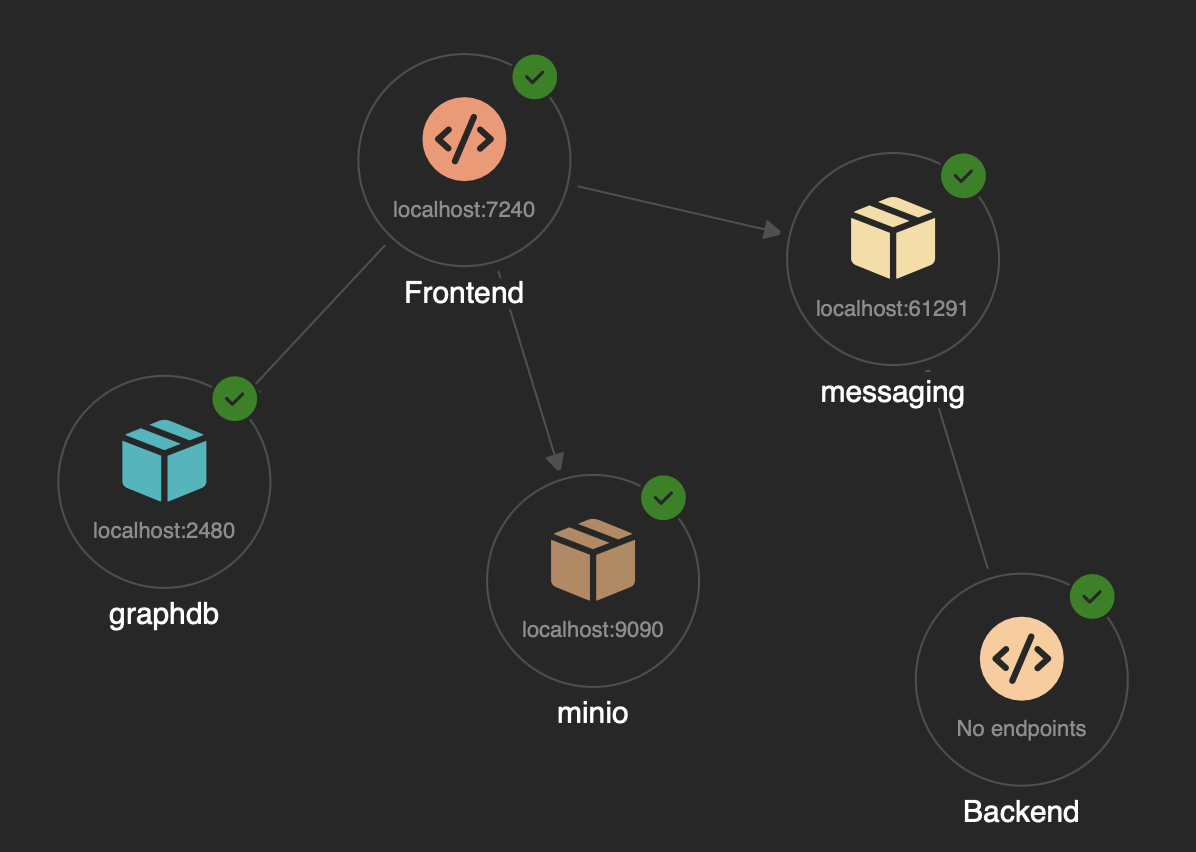
Time to look at what may be by far the most exotic technology choice in ahead: The use of a graph database in the form of the gremlin endpoint provided by Cosmos.
This decision was taken about 7 years ago – a good part of it was related to my excellent experiences with graph databases. Microsoft was already offering said endpoint for their Cosmos DB offering, and after some proof of concept we went in.
From today’s perspective, I’d rather choose boring tech™ over superior tech™. Case in point, it took me quite some time to settle on what a dockerized version of ahead could use from the list of technologies showcased on the tinkerpop (tinkerpop the tech vs gremlin the language, I assume, although I’ve never been 100% clear on where to draw the line between the two terms) page.
Generally, the tech feels fairly far away from .NET, even though Gremlin.NET is a capable client to access gremlin-enabled databases.
After some back and forth I settled for Arcade DB. It is a multi-model database (much like Cosmos is) and offers Gremlin-related capabilities, documented here.
The infrastructure
The DB is also available as container – the following code shows how the resource is registered with Aspire:
Gist not showing up? Most likely you're using Chrome. Reload the page to see the gist.
There’s a bit to unpack here:
In Aspire, we can define a connection string also as a resource. This method will then return the Graph DB resource
as well as the connection string necessary to connect to it as a resource as well. This is done
in the AppHost project as follows:
We can then reference the connection string from the project that needs it. The connection string will appear
in the system as a connect string with the name given to the resource (GraphDbConnectionString.Name).
Where things went awry for me is that the documentation of Arcade DB for running it in a container says that you should bind a specific folder in order to have the database files stored beyond container restarts. However, the graph db-related plugin defined its own specific location that was not bound to an external volume and hence all data created while having the solution running was lost after a restart. To counter this behavior I made a copy of the original properties file governing the behavior of the gremlin db plugin:
docker cp ahead_graphdb:/home/arcadedb/config/gremlin-server.properties ./gremlin-server.propertiesAnd then the file is adapted for the relevant setting to point to something in the folder already bound for database data.
gremlin.graph=com.arcadedb.gremlin.ArcadeGraphgremlin.arcadedb.directory=/data/graphThe readme of the solution contains instructions if you want to connect to the database via an interactive console.
The usage
The basic abstractions to use the DB follow those that we established many years ago at ahead:
public interface IAheadGraphDatabase{ public Task RunJob(IGremlinJob job); public Task<T> RunJob<T>(IGremlinJob<T> job);}
public interface IGremlinJob{ Task Run(IGraphContext graphContext);}
public interface IGremlinJob<T>{ Task<T> Run(IGraphContext graphContext);}
public interface IGraphContext{ Task Run(string query); Task<IReadOnlyList<TOut>> Run<TIn,TOut>(Func<GraphTraversalSource,GraphTraversal<TIn,TOut>> query);}This forces the packaging of database mutating & querying as jobs, where the constructor plays the role of accepting necessary parameters and the return value typically provides DTOs that are already useful for further processing.
The GraphTraversalSource and other Types come from the Gremlin.NET Nuget package,
that also comes with the methods to write a so-called traversal (aka query).
A simple usage example is implemented in the solution in the “Graph”-page:
Conclusion
After some searching and back & forth, I have a somewhat better feeling about how a migration could look like. Scaling could work with Arcade DB’s clustering features or lean into things we’ve learned around using different resources for different tenants in order to support different data residencies in order to scale horizontally.
Even so, I am still thinking how a migration to a document database could look like - simply for reasons of using even more boring tech™, something a long-lived product can profit immensely from.