2D-Historization in a graph database
In this series
- 2D or bitemporal Historization: A primer
- 2D-Historization in a graph database
- Simplify the bitemporal Neo4J query with a user-defined function
Note: This text assumes that you know a little bit about graph databases and Neo4J in particular. If you don’t know Neo4J, please have a read at Neo4J’s documentation
The introduction to 2D-historization dealt with the theory behind representing and reading state changes of your data in a model where we keep the time when the state change was recorded together with the actual time, the time where we want the state change to be applied in the context of whatever it is the application is representing.
My point of orientation when implementing 2D-historized data was Ian Robinson’s post on time-based versioned graphs
In here we find the following principles when representing data in the graph:
- We extract the immutable data about some entity into a single node. This would typically be the data that uniquely identifies the entity. Under certain circumstances this may be just some id, but depending on your case, more data could be stored in that node
- Any data that can change over time is extracted to another node, attached to the immutable one via a relationship that stores the actual and recorded time when the data node was created.
- Repeat for any additional changes that are introduced to the entity.
Here is some cypher to create an example:
CREATE (p:Person { id: 112245 })CREATE (pd:PersonData { name: 'Joe Bloggs' })-[:EXPANDS { recorded: 10, actual: 10}]->(p)CREATE (pd2:PersonData { name: 'Joe Gonzalez' })-[:EXPANDS { recorded: 20, actual: 30}]->(p)Consider the actual and recorded values to be e.g. days since inception…
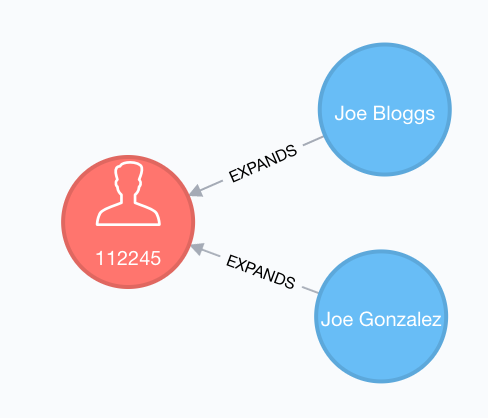
The query to get the right history of PersonData changes is pretty straightforward:
MATCH (pd:PersonData)-[r]-(p)WHERE p.id = 112245AND r.recorded <= 30RETURN r.recorded, r.actual, pd.nameORDER BY r.recorded DESC(assuming existence of only the EXPANDS relationship)
However, we’ve previously seen that some entries may be cancelled out, e.g. when you record a future state and later on you record a new state that will be valid before the previously recorded one.
We can consider the following example:
CREATE (p:Person { id: 665544 })CREATE (pd:PersonData { name: 'A. Brannigan' })-[:EXPANDS { recorded: 10, actual: 10}]->(p)CREATE (pd2:PersonData { name: 'A. Durington' })-[:EXPANDS { recorded: 20, actual: 40}]->(p)CREATE (pd3:PersonData { name: 'A. Lovegood' })-[:EXPANDS { recorded: 30, actual: 30}]->(p)The logic how such state changes should be considered is explained in the previous blog post. To recap:
- move backwards along the recorded time axis.
- add events to the history whose actual time lies before the last state collected
- ignore those whose actual time lies beyond the last state collected.
Can we express this in Cypher? Well, it’s not pretty, but it’s possible*):
MATCH (pd:PersonData)-[r]-(p)WHERE p.id = 665544 AND r.recorded <= 30WITH { data: pd, recorded: r.recorded, actual: r.actual } as dataWITH data ORDER BY data.recorded DESCWITH reduce(relevant = [], d in collect(data) |CASEWHEN last(relevant) IS NULL OR d.actual < last(relevant).actual THEN relevant+dELSE relevant END)AS dataUNWIND data AS finalRETURN final.actual, final.dataDepending at which point in time you look at the state you now get two different histories:
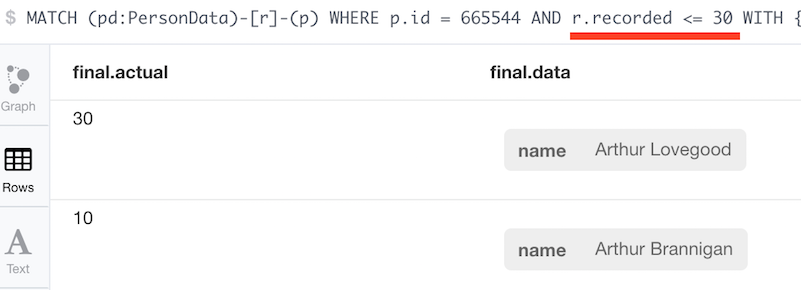
or
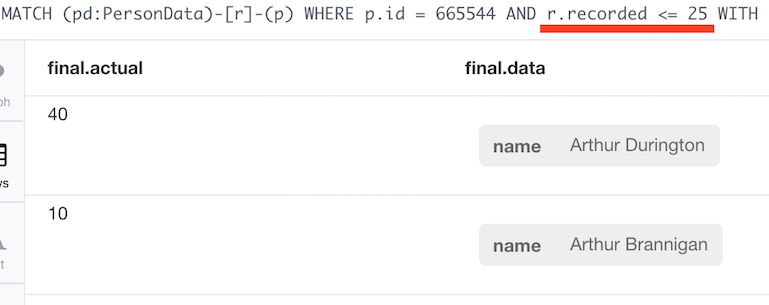
What the query does is to
- identify the immutable node we are interested in and establish the data we will be considering
- order it descending based on the recorded time
- reducing the data, thereby rejecting those states that have been cancelled by subsequent state entries.
As is often the case with graphs, there are quite a few ways you can go about storing data with meaningful relationships. Other representations could be
- Putting the emphasis entering the queries purely through a point in time. In this case you could try and construct a representation with the help of a time tree.
- Putting the emphasis on business transactions that summarize all state changes contained in said transaction.
As usual with graphs, think in advance the kind of questions you will want to ask :)
*) Disclaimer: I am no cypher expert. The query expresses the logic outlined in the first blog post with some additional noise, some compaction may still be possible.