remorse - the overall application structure
Before you look at remorse, you should consider learning about the basic building blocks of a redux application:
- View components : You will find that the view in this application is stateless. You notice that in the fact that all react components are written as functions, that is, they depend on their input and other stateless functions
- Reducer : They reduce an action, together with the the previous state, to a new state which describes the view
- Actions: Every change that the UI undergoes is triggered by some action in the application.
In the context of remorse we have trivial actions, e.g.
forceStopTraining() { clearInterval(timer); return { type: "TRAINING_STOPPED" };}or complex ones (see e.g. evaluateUserInput in Training/TrainingActions.js).
Let’s have a look at the overall structure of remorse:
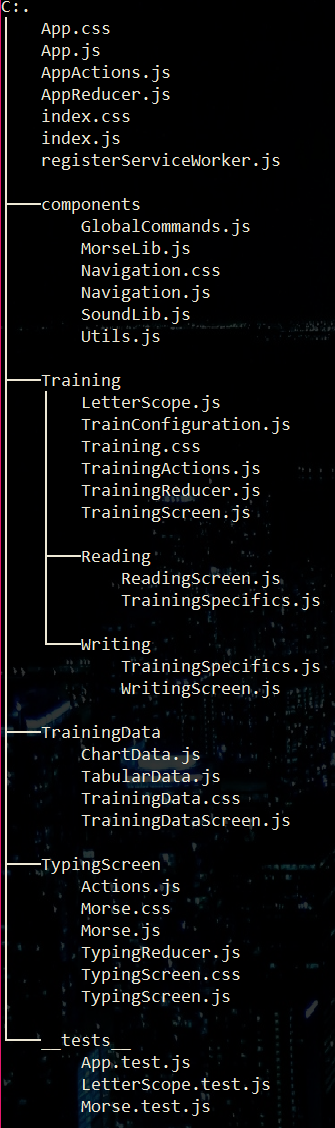
Generally speaking, code is separated by feature:
- Typing: Here you type & listen morse code
- TrainingData: Shows tables and charts with regard to your progress
- Training: Contains the training screens, Reading and Writing
One of the decisions early on was to decide whether the reading and writing screen would be different or just the same code base. The pros / cons are obvious.
- Different: The screens can easily progress independently, the danger being more boilerplate code, duplication etc.
- Same: Less code, but extension points with regard to the differences need to be introduced, making the code a little bit more complex.
Since the two screens are indeed very similar at this point in time, I decided for the latter, hence the Training folder with sub folders.
This means that some items require specifics, which are bundled in the Reading/Writing specifics files. Let’s have a look at one:
import createTrainingActions from "../TrainingActions";...const Actions = createTrainingActions({ trainDataStorageKey: APP_READ_TRAINDATA_KEY, nextLetterProvider, inputFromKey, expectedInputFromCurrentTrainingSet: morseCodeToChar});export default Actions;createTrainingActions then creates a closure and the actions it returns become bound to the training specifics, e.g.
export default function createTrainingActions({ trainDataStorageKey, ...}) { ... return { saveTraining() { ... storeObject(trainDataStorageKey, trainingData); } }The training view can now get training specific actions like such:
import TrainingScreen from "../TrainingScreen";import Actions from "./TrainingSpecifics";
const WriteTraining = connect(function(s) { return s.train.currentTraining || {};}, Actions)(TrainingScreen);The features are tied back together in the AppReducer:
import { combineReducers } from "redux";import train from "./Training/TrainingReducer";import typing from "./TypingScreen/TypingReducer";
const appReducer = combineReducers({ typing, train });export default appReducer;Notice that there is no reducer for displaying the training data. This is because the training data screen runs independently of the redux infrastructure. This is because it is (sort of) legitimate to have the routing run independently of the redux application itself. Of course it depends on what you want to be able to do, but for this application there were no major drawbacks in doing so. So, since looking at training data is purely a readonly screen and any changes are just navigational changes, it runs without connected components (connected here means components wired up to the redux infrastructure).
And finally, App.js ties the different features together:
<BrowserRouter basename={process.env.REACT_APP_BASENAME}> <Provider store={store}> <div id="root"> <Navigation /> <Route path="/typing" component={TypingScreen} /> <Route path="/test-writing-morse" component={WritingScreen} /> <Route path="/test-reading-morse" component={ReadingScreen} /> <Route path="/training-data" component={TrainingDataScreen} /> </div> </Provider></BrowserRouter>